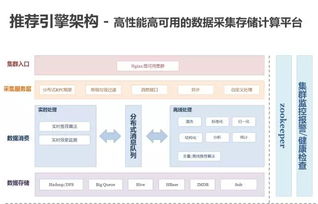
MySQL海量数据存储优化 数据处理与存储服务策略
随着数据量的爆发式增长,MySQL作为广泛使用的关系型数据库,在海量数据场景下面临着存储与性能的双重挑战。为了确保数据处理与存储服务的高效、稳定和可扩展,必须采取一系列综合优化策略。
一、海量数据存储架构设计
- 分库分表策略:当单表数据量超过千万级时,应考虑分库分表。通过水平拆分(如按时间、用户ID哈希)将数据分布到多个数据库实例或表中,可以有效减轻单点压力,提升并发处理能力。常用的中间件如ShardingSphere、MyCat可以帮助实现透明化分片。
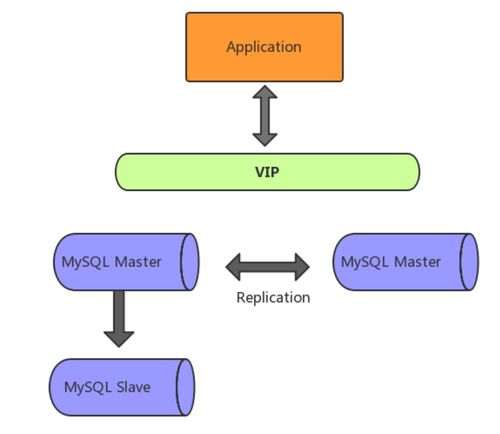
- 读写分离:通过主从复制架构,将写操作集中在主库,读操作分发到多个从库,不仅能提升读取性能,还能提高系统的可用性。结合负载均衡器(如ProxySQL)可以动态管理读写流量。
- 冷热数据分离:将历史冷数据迁移至归档表或低成本存储(如对象存储),热数据保留在高性能MySQL实例中,从而降低存储成本并保持核心业务的响应速度。
二、数据处理优化技术
- 索引优化:针对高频查询字段建立合适的索引(如组合索引、覆盖索引),避免全表扫描。定期使用
EXPLAIN分析查询执行计划,并注意索引失效场景(如函数操作、模糊查询前缀缺失)。 - 查询语句调优:避免使用
SELECT *,仅查询必要字段;优化JOIN操作,确保关联字段有索引;利用批量操作减少网络开销,例如使用INSERT ... VALUES (...), (...)替代多条单行插入。 - 异步处理与队列:对于耗时数据处理任务(如报表生成、数据清洗),引入消息队列(如RabbitMQ、Kafka)进行异步解耦,防止长时间事务阻塞数据库连接。
三、存储服务性能提升
- 硬件与配置调优:根据业务负载选择高性能SSD存储,并调整MySQL配置参数(如
innodb<em>buffer</em>pool<em>size设置为系统内存的70-80%,innodb</em>log<em>file</em>size适当增大以减少日志切换频率)。 - 数据压缩与编码:启用InnoDB表压缩(
ROW_FORMAT=COMPRESSED)可减少磁盘占用,同时优化字符集(如使用utf8mb4替代utf8)确保兼容性与存储效率。 - 监控与预警体系:部署监控工具(如Prometheus+Grafana、Percona Monitoring and Management),实时跟踪关键指标(QPS、慢查询、连接数、磁盘IO),并设置阈值预警,以便及时扩容或干预。
四、数据安全与容灾
- 备份策略:采用全量备份与增量备份结合的方式,利用
mysqldump、XtraBackup等工具定期备份,并将备份数据存储在异地或云存储中,确保数据可恢复性。 - 高可用部署:通过主从切换(如基于MHA、Orchestrator)或集群方案(如MySQL Group Replication、Galera Cluster)实现故障自动转移,最大限度减少服务中断时间。
- 数据生命周期管理:制定明确的保留策略,自动清理过期数据,结合分区表(Partitioning)可以高效删除历史分区,避免大表删除操作带来的性能影响。
MySQL海量数据存储与优化需要从架构设计、数据处理、存储服务及容灾等多个维度协同推进。随着云原生技术的发展,结合云数据库服务(如AWS RDS、阿里云RDS)的托管能力,可以进一步降低运维复杂度,构建弹性、可靠的数据处理与存储服务体系。持续的性能测试、监控迭代和架构演进,是应对数据增长挑战的不二法门。
如若转载,请注明出处:http://www.rejfdrw.com/product/61.html
更新时间:2026-06-19 02:31:06