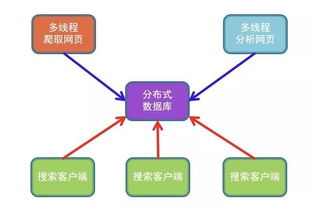
分布式数据库驱动 全文搜索系统的数据处理与存储新范式
在信息爆炸的时代,高效、精准的全文搜索能力已成为众多应用的核心需求。传统上,搜索引擎常依赖于如Elasticsearch或Solr这类专有搜索服务器,它们虽性能强大,但架构复杂,运维成本高,且与业务数据库存在数据同步与一致性的挑战。如今,一种另辟蹊径的方案正获得越来越多的关注:直接利用现代分布式数据库构建全文搜索系统,实现数据处理与存储服务的深度统一。
一、核心理念:融合而非分离
此路径的核心在于摒弃“专用搜索中间件+业务数据库”的分离架构,转而选择具备强大原生全文搜索能力的分布式数据库(如Google Spanner的衍生开源实现、CockroachDB,或深度集成了搜索引擎的NewSQL数据库等)。这些数据库不仅提供高可用、强一致、可水平扩展的分布式事务与存储,更将倒排索引、分词、相关性评分等全文搜索功能作为一等公民内置其中。
数据处理与存储服务因此被统一到同一套架构和数据模型下。数据只需写入一次,即可同时支持联机事务处理(OLTP)、联机分析处理(OLAP)和复杂的全文检索查询,从根本上消除了数据冗余、同步延迟与一致性问题。
二、数据处理:流式、批处理与索引构建一体化
在数据处理层面,系统可以利用分布式数据库的自身特性实现高效流程:
- 实时数据摄入:通过数据库原生的变更数据捕获(CDC)流或直接写入,文本数据被实时持久化。数据库的事务保障确保了数据原子性、一致性。
- 内置文本处理:在数据插入或更新时,数据库内核自动触发文本处理流水线,包括:
- 分词与归一化:利用内置或可扩展的分词器对文本进行切分、词干还原、去除停用词等。
- 倒排索引构建:在后台异步或实时地构建和维护倒排索引,索引数据作为表的一部分或内部结构进行分布式存储,并利用数据库的复制与分片机制实现高可用与负载均衡。
- 批处理与ETL整合:对于历史数据批量导入或复杂转换,可直接利用数据库支持的大规模并行处理框架或与其紧密集成的计算引擎(如Spark)在存储层附近进行计算,避免不必要的数据移动。
三、分布式存储:索引与数据共存的优势
存储服务直接受益于分布式数据库的成熟特性:
- 全局一致性索引:倒排索引与源数据共享同一份分布式事务日志,确保搜索视图与数据源在任何时刻的强一致性或最终一致性(可根据业务配置)。索引分片随数据分片自动分布,查询可被高效路由。
- 弹性扩展与高可用:存储与计算分离(或紧密协同)的架构允许独立扩展存储节点或计算节点。索引和数据通过多副本机制保障可用性,节点故障自动转移,对搜索服务透明。
- 统一的安全与运维:权限控制、审计日志、备份恢复、监控告警等全部基于同一套数据库管理系统,极大简化了运维复杂度。
四、挑战与考量
尽管前景光明,采用此路径仍需审慎评估:
- 功能成熟度:相比深耕多年的专用搜索引擎,分布式数据库的全文搜索功能在高级特性(如复杂的同义词、词性分析、自定义评分模型、近似搜索等)上可能仍有差距。
- 性能调优:针对超大规模文档集和高并发搜索场景,需要深入理解数据库的索引机制、查询优化器与执行计划,进行针对性调优。
- 生态工具:围绕传统搜索引擎建立的庞大生态(如可视化工具、语言客户端、管理平台)可能需要时间适配或重新开发。
五、
利用分布式数据库构建全文搜索系统,代表了一种追求架构简洁性、数据一致性和运维效率的先进思路。它将搜索从独立的“子系统”深度融合进核心数据平台,使得数据处理与存储服务能够无缝支撑从精准关键字查询到复杂分析的全方位需求。对于正在构建新一代数据密集型应用的企业而言,这不失为一条值得深入探索和评估的“蹊径”,有望在降低系统总拥有成本(TCO)的提升整体数据服务的敏捷性与可靠性。
如若转载,请注明出处:http://www.rejfdrw.com/product/35.html
更新时间:2026-06-19 16:26:06