云原生数据湖101 数据处理与存储服务详解
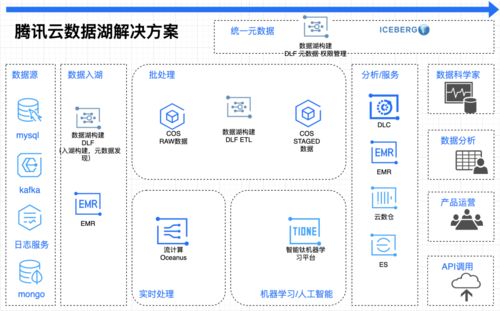
随着云原生技术的快速发展,数据湖已成为企业数据架构的核心组成部分。云原生数据湖结合了云计算的弹性、可扩展性和成本效益,为数据处理和存储提供了强大的解决方案。本文将深入探讨云原生数据湖中的数据处理和存储服务,帮助您全面理解其核心概念与应用。
一、云原生数据湖概述
云原生数据湖是一种基于云平台构建的数据存储和处理架构,支持结构化、半结构化和非结构化数据的集中存储。与传统数据仓库相比,数据湖具有更高的灵活性和可扩展性,允许企业在同一平台上进行数据摄取、存储、处理和分析。
二、数据处理服务
数据处理是数据湖的核心功能之一,云原生环境提供了多种高效的数据处理服务:
- 数据摄取与集成:通过云原生工具(如AWS Glue、Azure Data Factory)实现多源数据的自动化摄取和集成,支持批处理和实时流式数据处理。
- 数据转换与清洗:利用无服务器计算服务(如AWS Lambda、Azure Functions)或专用数据处理引擎(如Apache Spark on Databricks)进行数据清洗、格式转换和丰富化。
- 数据处理引擎:云平台通常提供托管的数据处理服务,例如Amazon EMR、Google Dataproc,支持大规模分布式计算,满足复杂的数据处理需求。
- 流式处理:对于实时数据,云原生服务如Amazon Kinesis或Azure Stream Analytics可实现低延迟的数据流处理,适用于IoT、日志分析等场景。
三、数据存储服务
数据存储是数据湖的基础,云原生存储服务提供了高可用、持久且成本优化的解决方案:
- 对象存储:云平台的对象存储服务(如Amazon S3、Azure Blob Storage)是数据湖的理想存储层,支持海量数据存储,并提供高耐久性和可扩展性。
- 数据分层与生命周期管理:通过冷、热存储分层(如Amazon S3 Glacier、Azure Archive Storage)优化存储成本,自动管理数据生命周期。
- 元数据管理:使用服务如AWS Glue Data Catalog或Azure Purview进行元数据管理,确保数据的可发现性、治理和一致性。
- 安全与合规:云原生存储服务内置加密、访问控制和审计功能,帮助满足数据安全性和合规要求(如GDPR、HIPAA)。
四、数据处理与存储的集成
在云原生数据湖中,数据处理和存储服务紧密集成,形成端到端的数据流水线:
- 事件驱动架构:通过云原生事件服务(如Amazon EventBridge、Azure Event Grid)触发数据处理任务,实现自动化工作流。
- 数据湖屋(Lakehouse)模式:结合数据湖的灵活性和数据仓库的性能,使用Delta Lake、Apache Iceberg等技术,在存储层支持ACID事务和高效查询。
- 监控与优化:利用云平台监控工具(如Amazon CloudWatch、Azure Monitor)跟踪数据处理和存储性能,并根据需求进行自动扩展和成本优化。
五、优势与挑战
优势:
- 弹性与可扩展性:云原生服务可根据负载自动扩展,避免资源浪费。
- 成本效益:按使用量付费模型和存储分层降低了总体拥有成本(TCO)。
- 敏捷性:快速部署和集成加速了数据项目的上市时间。
挑战:
- 数据治理:在分布式环境中确保数据质量、一致性和安全性需要精细的策略。
- 技能需求:团队需掌握云原生工具和数据处理技术。
- 厂商锁定风险:依赖特定云平台的服务可能导致迁移困难。
六、总结
云原生数据湖的数据处理和存储服务为企业提供了强大、灵活的数据管理能力。通过合理利用云平台的服务,企业可以构建高效、安全且成本优化的数据架构,支持从批处理到实时分析的多样化用例。随着技术的演进,云原生数据湖将继续推动数据驱动决策的创新。
如若转载,请注明出处:http://www.rejfdrw.com/product/16.html
更新时间:2026-04-18 09:34:49









