LinkedIn 数据分析技术栈的演进与实践 数据处理与存储服务的进化之路
引言:数据驱动的基石
在当今的商业世界中,数据被视为新时代的石油,而 LinkedIn 作为全球领先的职业社交平台,其数据驱动的决策文化和产品创新,离不开一个强大、灵活且不断演进的数据技术栈。从早期的单体架构到如今复杂的多技术生态系统,LinkedIn 在数据处理和存储服务方面的实践,为业界提供了宝贵的经验。本文将深入探讨其技术栈的演进历程、核心组件及其背后的设计哲学。
第一阶段:奠基与统一(早期至2010年代初)
LinkedIn 的数据之旅始于对内部业务数据的集中化处理需求。早期,其技术栈相对简单,核心是传统的 Oracle 数据库 和基于 Hadoop 的批处理系统。
- 数据处理:主要依赖 Hadoop MapReduce 进行大规模的离线批处理分析。工作流调度工具如 Azkaban 被开发出来,以管理和协调复杂的批处理作业。数据处理周期通常以天为单位,支持会员增长、搜索优化等核心业务报表。
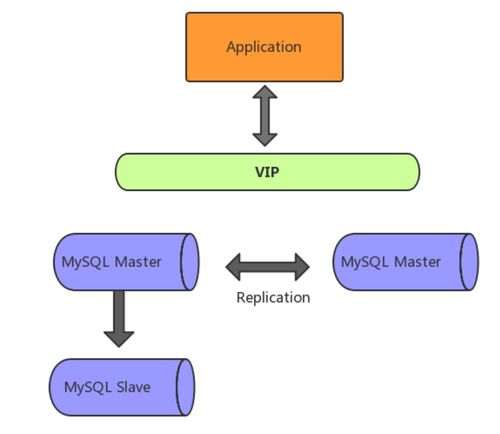
- 数据存储:在线事务处理(OLTP)由关系型数据库(如 Oracle)承担。而海量的、半结构化的日志和用户行为数据则存储在 HDFS 上,形成了数据湖的雏形。此时,Voldemort(一个分布式键值存储系统)作为 LinkedIn 自研的低延迟 NoSQL 数据库,开始服务于个性化推荐等场景。
这一阶段的关键词是 “批处理” 和 “集中化”。技术栈解决了“存得下、算得动”的基本问题,但实时性不足,数据消费门槛较高。
第二阶段:实时化与平台化(2010年代中期)
随着业务对实时洞察和即时个性化需求的爆炸性增长,LinkedIn 的技术栈开始向实时流处理全面演进。
- 数据处理:标志性事件是开源流处理框架 Apache Samza 的诞生。Samza 与 Apache Kafka(同样源自 LinkedIn)深度集成,构建了高性能、有状态、容错的实时流处理管道。这使得实时关注流、消息通知、Who-Viewed-Your-Profile 等功能成为可能。Apache Spark 逐渐取代 MapReduce,成为离线批处理和准实时(微批处理)计算的新引擎,大幅提升了处理效率。
- 数据存储与服务:
- Kafka 不仅作为消息队列,更演变为 “永不停歇的实时数据中枢” ,所有应用和系统的事件日志都流经 Kafka,构成了公司级的单一事实来源。
- 为了高效服务在线查询,LinkedIn 开发了 Pinot,一个分布式、列式的实时分析数据库。Pinot 能够直接从 Kafka 摄取数据,并在亚秒级延迟内回答复杂的即席查询,赋能了实时仪表盘和交互式分析。
- Espresso 作为另一个自研的分布式文档存储系统,提供了强一致性的 NoSQL 服务,支撑了个人资料、公司主页等核心数据的低延迟访问。
这一阶段的核心是构建 “端到端的实时数据管道” 。Kafka-Samza-Pinot 构成了实时数据分析的黄金三角,数据处理从 T+1 迈入了秒级时代。
第三阶段:智能化、云原生与治理(近年至今)
当前,LinkedIn 的数据技术栈在持续演化的基础上,重点聚焦于提升效率、降低复杂性和加强治理。
- 数据处理:Apache Beam 模型开始被采纳,以期统一批处理和流处理的编程范式。AI 和机器学习 深度融入数据管道,例如利用机器学习模型进行数据质量自动检测和异常预警。数据处理更加 “声明式” 和 “自动化” 。
- 数据存储与湖仓一体:面对内部多达数十个数据存储系统,LinkedI正在推动 “数据湖仓一体” 架构。通过 Apache Hudi 或 Iceberg 这样的表格格式层,在对象存储(如 Azure Data Lake)之上构建兼具数据湖灵活性和数据仓库管理能力的统一数据层,简化架构,提升数据共享和治理效率。
- 数据治理与可观测性:随着数据资产爆炸式增长,强大的数据治理变得至关重要。LinkedIn 投资于统一的数据目录(如 DataHub, 已开源)、血缘追踪、数据质量监控和访问控制平台。这些工具确保了数据的可发现、可信、可理解与安全合规。
- 云原生演进:在微软旗下,LinkedIn 的技术栈也在积极拥抱云原生理念,探索容器化部署(K8s)、无服务器计算与托管云服务,以进一步提升资源弹性和运维效率。
这一阶段的主题是 “增效” 与 “治理” 。技术栈在追求性能极限的更关注如何让海量数据资产安全、高效、便捷地产生业务价值。
实践启示与核心原则
回顾 LinkedIn 的演进之路,可以出几条关键的实践原则:
- 需求驱动,业务对齐:每一次重大技术演进都源于明确的业务需求(如实时个性化),而非纯粹的技术追逐。
- 构建中枢,统一流:确立 Kafka 作为公司级的实时数据中枢,是其实时能力得以实现的基石。
- 开源与自研结合:积极拥抱和贡献开源(Kafka, Samza, Pinot, DataHub),同时对无法满足独特性能或规模需求的核心场景进行自研(如 Voldemort, Espresso)。
- 关注全链路,而非单点:从数据产生、摄取、处理、存储到服务与消费,构建完整、健壮且可观测的数据管道。
- 数据治理是增长后的必然:当数据规模和应用复杂度达到临界点,系统的数据治理与元数据管理成为技术栈不可或缺的一部分。
###
LinkedIn 的数据处理与存储技术栈是一部从集中批处理到实时智能分析的生动进化史。它展示了一个顶级数据驱动公司如何通过持续的技术创新和架构迭代,将数据转化为核心竞争力和产品优势。其演进路径不仅是一系列技术选型的集合,更是一种面对数据挑战时,坚持平台化、实时化、智能化并兼顾治理与效率的系统性思维体现,为各行各业构建现代化数据基础设施提供了极具价值的蓝图。
如若转载,请注明出处:http://www.rejfdrw.com/product/32.html
更新时间:2026-06-19 05:06:32